Le Big Data et L’IA c’est quoi au juste ?
Définition du Big Data
La première question que l’on doit se poser c’est pourquoi ? Pourquoi parle-t-on aujourd’hui de Big Data ? La première réponse c’est parce qu’aujourd’hui nous le pouvons. Oui nous pouvons en parler, en discuter et même tenter de donner une explication à ces concepts là.
La première raison c’est que nous avons enfin la capacité machine et ce n’est qu’un début. Vous connaissez sans doute les lois universelles de l’informatique notamment la Loi de Moore ? En effet, Gordon Moore avait théorisé en 1975 le concept suivant : « le nombre de transistor sur une puce de silicium double tous les dix-huit mois ou tous les deux ans ». Le corollaire qu’il faut en faire c’est de dire que les ressources informatiques doublent tous les dix-huit mois. Cela s’est vérifié entre 1965 jusqu’en 2017 même si actuellement il y’a un léger ralentissement (Cf : Article Journal du Net ).
La deuxième raison c’est que 90 % des données disponibles dans le monde aujourd’hui ont été produites durant ces dernières années. Une tendance qui va continuer à s’accélérer avec l’explosion des objets connectés.
Littéralement, le terme Big Data signifie donc les mégadonnées ou encore données massives. Nous produisons environ 2,5 trillons d’octets tous les jours. Ce sont des informations qui proviennent de partout : les messages que nous envoyons, les vidéos que nous publions, notre activité sur les réseaux sociaux, les informations produits par nos objets connectés notamment nos Smartphones avec les signaux GPS, nos transactions bancaires en ligne ….et bien d’autres encore.
Les géants du numérique (GAFA) ont donc été les précurseurs dans ce domaine. Pour rappel, s’il l’on parle aujourd’hui de Big Data c’est parce qu’il y’a eu trois phases de digitalisation. D’abord une phase de plateformisation et de numérisation des données avec les technologies produites par les GAFA, ensuite une numérisation des services avec les NATU et la troisième étape celle que nous vivons actuellement avec la numérisation des objets grâce à l’IOT (Internet Of Things).
Le flux d’information que nous produisons ne cesse donc de croitre de façon exponentielle depuis quelques décennies. Le rythme de croissance des données est vertigineux. Ce volume de données colossales ne peut plus être collecté, stocké, géré et exploité par les solutions informatiques traditionnelles ni par l’humain à lui seul. Pour trouver donc des solutions technologiques adéquates, une première phase de clarification conceptuelle du Big Data a vue le jour avec l’adoption de la régle des 3V (Volume, Vélocité et Variété).
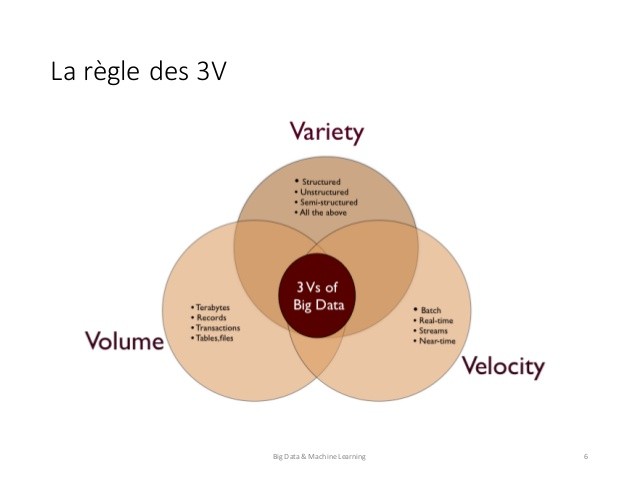
Vous trouverez ci-dessous un extrait tiré du blog Business et Décision qui traite bien de ce fameuse régle des 3V.
« Volume
Dans les systèmes d’information en place dans les entreprises, les volumes de données traités se mesurent en téraoctets. Le challenge immédiat de l’IT traditionnel est d’être en capacité de traiter des Pétaoctets et bientôt des Exaoctets puis des Zettaoctets.
S’ensuivent une longue liste de questions auxquelles les spécialistes doivent apporter une réponse à plus ou moins long terme : quels sont les coûts ? Quels sont les outils de stockage et de traitement en temps réel ? Quelles sont les méthodes à adopter pour analyser l’information ? Quels sont les moyens pour archiver ? Les technologies émergentes proposent quelques débuts de réponse.
Vélocité
L’importance de l’immédiateté et de l’instantanéité pour recevoir ou émettre des informations par chacun d’entre nous et pour toutes les activités, professionnelles ou personnelles, du quotidien contraigne les organisations à améliorer leurs vitesses de réaction et d’anticipation. L’information n’est plus statique, mais elle devient un facteur de changement dynamique. Dans ce contexte, comment l’intégrer en temps réel dans les schémas de données actuels conçus pour être alimentés en temps différé ? Comment canaliser ce déluge d’information dans des flux maîtrisés ? Comment faire parvenir la bonne information au bon moment et au bon destinataire ?
Variété
Texte, images, photos, vidéos, quel que soit le format de l’information, les données, structurées ou non structurées, requièrent un nouveau savoir-faire pour être assimilées puis analysées. L’exploitation et le traitement de l’information aussi variée, tant par la forme que par le contenu, sont difficilement réalisables en dehors du support initial.
En conséquence, une approche d’indexation, de recherche sémantique et de navigation intra- et inter- applications s’impose pour l’exploitation de ces nouveaux médias, sans oublier la nécessité de modélisation de phénomènes complexes.
C’est précisément pourquoi la gouvernance des données, leur protection, la gestion de leur qualité constituent les nouveaux enjeux des systèmes d’information, puisque l’information ne provient pas nécessairement de sources internes et contrôlées et qu’elle ne correspond pas à priori et nécessairement aux caractéristiques attendues en termes de format, de qualité et d’intégrité.
Après les 3V…
Les cabinets d’étude et de conseil en marketing sont très actifs sur les marchés qui embarquent les nouvelles technologies. De nombreux qualificatifs sont venus s’ajouter aux 3V tels que Véracité, Valeur, Variabilité, auxquels sont associées des notions de compétences et de coûts. Répondre aux caractéristiques des 3V, dans les premières mises en place de systèmes d’information, est déjà un challenge. Il convient néanmoins de n’écarter aucune dimension dans l’analyse, en particulier la notion de Véracité ».

Pour aller encore plus loin, nous vous recommandons de lire cet article sur les 5V du Big Data à savoir : Volume, Vélocité, Variété, Véracité et Valeur.